复杂运维场景下,如何实现分钟级的故障根因定位
2016-06-27 09:25:00 来源:来源:高效运维 评论:0 点击:
在超级互联网公司,随着服务器规模都早早迈过10万台量级,加之业务模式的多样性和IT架构的云化迁移,其IT运维团队面临的挑战与日俱增,常规的系统和经验都需要不断迭代更新。本文介绍在超级互联网公司如何基于网络的故障根因自动定位技术,提高故障定位速度,从而提高业务可用性。
作者介绍
熊亚军
灵犀技术总监,原百度系统部高级项目经理,负责百度IT基础设施监控团队,其带领的团队经历了百度服务器规模迈入几十万量级,网络架构数次演进,对服务器尤其是网络层的监控和运维自动化智能化有丰富的经验。
开篇:
在超级互联网公司,随着服务器规模都早早迈过 10 万台量级,加之业务模式的多样性和 IT 架构的云化迁移,其 IT 运维团队面临的挑战与日俱增,常规的系统和经验都需要不断迭代更新。
本文将给大家介绍在超级互联网公司如何基于网络的故障根因自动定位技术,提高故障定位速度,从而提高业务可用性。
规模效应和云的效应极大提升了运维的复杂性
首先,我们先来看看超级互联网公司的业务架构示例图:
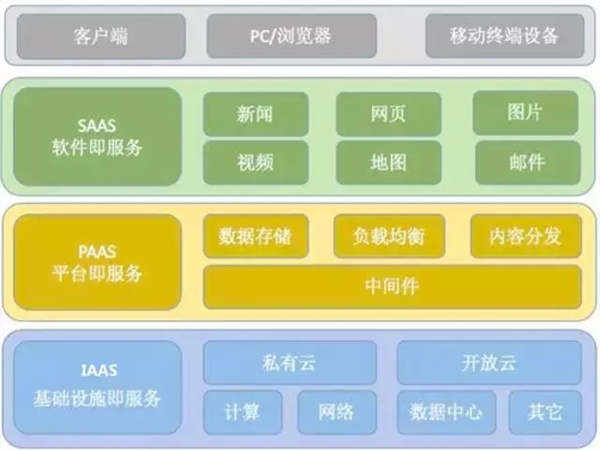
在超级互联网公司中,通常不同的层次都由不同的团队来负责运维管理,同层次不同的硬件/系统/应用都由不同的小组来负责运维管理。
就基础设施即服务这层来说,随着IT设备规模的不断增加,IT 设备故障的告警种类与告警数量也随之急剧增加。
告警的多面性、冗余性、耦合性,导致某些核心层面的故障会引起大面积告警的现象,而这些告警又有可能分属不同小组,运维人员处理故障会增加排查问题的难度以及增加小组间沟通成本。
同时因为对故障信息缺乏统一的管理,无法对告警系统进行反馈优化,致使误报漏报频出。同样也无法进行全面的故障信息统计分析,不知道如何对基础设施资源进行风险管理。
众所周知,IT基础设施层的运维工作,直接影响公司服务稳定性。一次服务中断事件便会对公司造成极大的经济损失。
但正如上述现状描述中提到的问题:
- 运维平台繁杂多样,
- 运维小组之间沟通滞后,
- 告警信息共享程度低,
- 工程师水平参差不齐,故障处理自动化程度较低。
告警系统缺乏有效的反馈机制进行系统优化,同时缺少全面有效的故障信息沉淀,无法帮助预算与评估采购系统进行合理采购。
这些都极大约束了运维水平的与时俱进,新的方法论和新的运维技术有迫切的内部需求。
我们收敛汇总一下复杂运维场景下的主要痛点:
- 如何在告警风暴时压缩告警
- 如何快速从大量告警中找到故障根源
- 如何提高不同运维小组的故障处理协作效率
- 如何实现对IT基础设施的风险管理
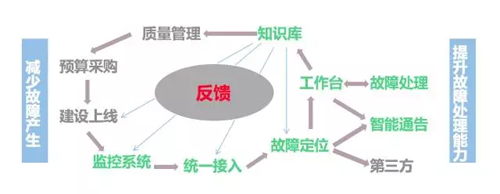
如何应对?打造以故障定位为核心的运维生态体系!
基于上述背景下的痛点问题,一套以故障定位为核心的运维生态体系的建立便成为高逼格的不可或缺:
- 统一故障信息入口,使用机器学习的算法对信息进行分类整合和推理,自动定位故障生成case,设计开发统一故障处理平台,通知工程师来平台进行处理故障。
- 同时将所有数据进行沉淀分析,反馈给告警系统和质量管理系统,提高故障处理效率,加强基础设施风险管理。
而在这套生态体系中,故障自动定位技术便是体系是否能够成功建立的核心要素。
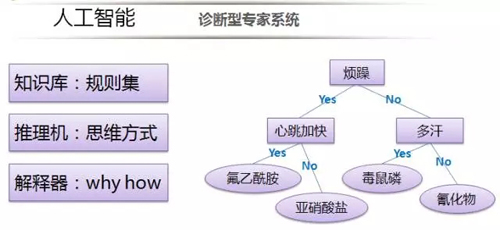
故障根因自动定位简要科普
故障根因自动定位系统为人工智能的分支,属于诊断性专家系统,专家系统通常包含:
- 人机交互界面
- 知识库
- 推理机
- 解释器
- 综合数据库
- 知识获取
其中最重要的是知识库和推理机。知识库用于专家经验的存储,是一种静态规则,推理机根据现象结合知识库中的规则反复推理得出结论。规则集的组成形式有多种方式,本文重点介绍的是二叉决策树。
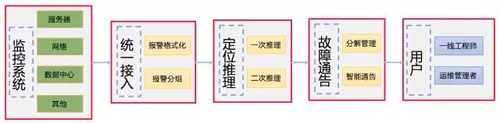
故障根因定位系统的设计架构系统
故障根因自动定位系统主要由监控系统、接入系统、推理系统、通告系统四个部分组成,分别的功能如下:
- 监控系统:监控系统负责各类探针数据的采集,根据监控规则产生告警。
- 接入系统:接入系统负责对各类监控系统的告警信息进行汇总并格式化处理。
- 推理系统:推理系统根据专家推理树进行故障根因定位推理,定位最终告警原因,确定故障根源。
- 通告系统:通告系统根据定位出的故障根因进行故障信息通告。
看个实际案例,看看到底能解决啥问题?
故障推理算法是整个故障定位系统的核心,这里重点阐述下故障推理算法的实现方式。
故障定位算法采用机器学习中的二叉决策树的方式实现:
- 一方面希望将故障所产生的所有告警信息整合为一条信息,减少告警量。
- 另一方面希望能够智能定位出故障点,减少工程师排查问题的时间,并引入自动化处理。
以某公司网络故障根因定位为例,实现上述目标需要三步:
第一步:将问题排障过程的经验提炼成二叉决策树。
第二步:将告警信息按照时间分片算法进行分类分组。
第三步:将分组的告警信息输出给决策树进行自动推理输出推理结果。
看看推理树是怎么构建的呢?
根据某公司目前网络故障时的告警特点和网络工程师运维的特点,得出下面的一些结论,而这些结论可帮助我们构建出经验推理树。
A、告警信息是分层次的:
- 第一层是交换机级别,如ROUTER_ID、CPU、TM告警。
- 第二层次是板卡告警,比如板卡芯片问题,板卡故障。
- 第三层次是端口告警,LINK-NEW告警等与端口相关的告警。
B、每一层的告警又可分为原子告警,衍生性告警。
比如:
第三层告警,LINK-NEW便是衍生性的告警,而PORT DOWN的告警为原子告警,即PORT DOWN了一定会有LINK-NEW的告警,反之不然。
根据以上结论,故障定位的原则为:重要性从最高层往最低层报,每层中重要性从原子告警到衍生性告警报。
比如:
收到了ROUTER_ID,PORT DOWN, LINK-NEW的告警,那么只需报ROUTER_ID的告警。
如果只有PORT DOWN, LINK-NEW的告警,就重点报`PORT。
DOWN的告警,如果只有LINK-NEW的告警,则只能报LINK-NEW`的告警。
引入故障追踪列表,比如第二层的【BOARD告警】引起第三层的告警【PORT、OSPF、LINK-NEW】,每个故障追踪列表形成一个Case,即Case的生成过程不是以某交换机为单位,而是以故障追踪列表为单位。
根据上述的分析,设计推理树如下图所示:
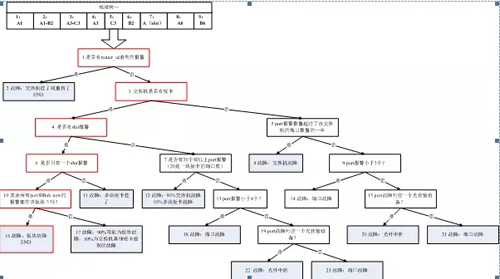
没太看明白?看看推理树的构建原则和实现方式
A、推理树的构建有以下四个原则:
原则一:告警从高层向底层,在逻辑层次上面,越根源性的告警越先判断。
例如:
A出现问题必然导致B出现问题,B出现问题必然导致C出现问题,在逻辑层次上面,A的根源性最高,当A、B、C告警同时到达,先判断A,判定A、B、C故障的根因为A。
在告警关联度上面,越明确关联的告警越先判断。
例如:
故障A对应有A1、A2、A3三种告警,关联度依次为A1 > A2 > A3,先判断A1,由A1直接确定A1、A2、A3的故障根因为A。
原则二:从原子到衍生告警。
原则三:推理树的建立根据告警来定。
原则四:验证规则,根据经验和知识库来定。
B、推理过程实现,有以下三种方式:
方式一:
给出特征 —> 推理机 —> 结论 —> 验证 —> 发出结果
方式二:
自主收集特征 —> 推理机 —> 结论 —> 验证 —> 发出结果
方式三:
数据 —> 根据特征设计的推理机 —> 结论 —> 验证 —> 发出结果
简单来说,方式一就是半人工方式、方式二就是简单机器学习方式、方式三就是智能机器学习方式。
来个总结吧!4步搭建你的故障根因定位系统
看完是不是有点小激动,想动手试试如何构建一套智能故障根因定位系统,需要如下几个步骤:
第一步:构建CMDB
CMDB是监控系统的基础,数据部分通常分为静态、动态两大类。
就网络设备而言,静态数据通常包括:
- 机框
- 矩阵
- 板卡
- 模块
- 端口
动态数据通常包括:
- IP地址
- 路由
- 端口状态
- 端口流量
第二步: 告警标准化
需要统一告警信息的格式,便于故障定位系统提取关键特征级并进行分类分组。
第三步:梳理告警关系
理清告警之间的关联关系,关联关系需要是逻辑上面的,形成必要的关系,例如A是B上游模块,A出现问题必然会导致B出现问题。
第四步: 构建推理树
根据人工故障定位判断逻辑,构建推理树,设定每个推理节点的判决条件。
OK啦!做完以上几步,您就搭建了一个简单的故障根因自动定位系统,通过对每个推理节点判断条件的不断优化,您可以不断提升故障自动定位准确率,让您的运维效率得到大幅提升,IT运营水平逐步与BAT等超级互联网公司运营水平对齐。
如果您需要任何帮助,也加入由灵犀linkedsee和高效运维共同建立的微信群,与本文作者和更多同行进行交流。
同时您也可以免费体验目前灵犀linkedsee对外发布的产品。
【编辑推荐】
【责任编辑:武晓燕 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
