传统运维 VS 互联网运维:从哪来,到哪去?
2016-05-05 14:20:00 来源:来源:高效运维 评论:0 点击:
近一年,关于传统运维与互联网运维的探讨越来越多,在运维体系快速变革地环境下,运维未来的走向,便成为运维行业的关注点。那么:到底什么是传统运维体系?什么是互联网运维体系?他们的特点,异同在哪?从哪里来到哪里去?

作者介绍
王天维,从事运维工作近十年,精通网络技术,CCIE专家。专注云计算、SDN、数据中心网络架构设计。
韩晓光,专业运维,兼职开发,干过商务。信息系统项目管理师、ITIL Foundation认证、IBM CATE、RHCE。著有《系统运维全面解析:技术、管理与实践》一书。
概述
近一年,关于传统运维与互联网运维的探讨越来越多,在运维体系快速变革地环境下,运维未来的走向,便成为运维行业的关注点。
那么:
到底什么是传统运维体系?
什么是互联网运维体系?
他们的特点,异同在哪?
从哪里来到哪里去?
本文将从以下角度探讨两大运维体系。
- 商业封闭式系统架构 vs 开源系统架构辨析
- 传统运维 vs 互联网运维辨析
- 去IOE运动辨析
- 运维发展趋势辨析
1、商业封闭式系统架构 vs 开源系统架构辨析
每个单位组织的IT环境,不论大小复杂度,总会有个系统架构层次。有了这个架构体系,那所有的运维事情大体都围绕着这个系统架构上的每个元素及整体进行运维保障工作。
运维体系架构从某种角度可以划分为如下两种:
- A. 商业封闭式系统架构(IOE架构)
- B. 开源系统架构
通常我们会将围绕商业封闭式系统架构(IOE架构)的运维视作传统运维,将围绕开源系统架构的运维视作互联网运维。
就上述两种运维体系,下文做一些辨析。
A. 商业封闭式系统架构(IOE架构)
典型的即以使用IOE(IBM、Oracle、EMC)产品软硬件为主要元素的系统架构。
IOE架构以纵向扩展为特点,通过增加CPU、内存、扩展柜、冗余备件等方式来提高处理能力及稳定性。
该架构的处理能力主要取决于单台(套)设备(系统)的最大扩展能力,很难通过增加设备(系统)数量来增加处理能力,换句话说该架构很难通过扩大集群规模的方式来解决问题。
随着纵向扩展的规模增大,它的实施技术难度、管理复杂度以及隐患风险都会成比例大幅上升。基于IOE架构的典型企业如:金融业、电信业、能源业、交通运输业。IOE典型的系统架构如下图所示。
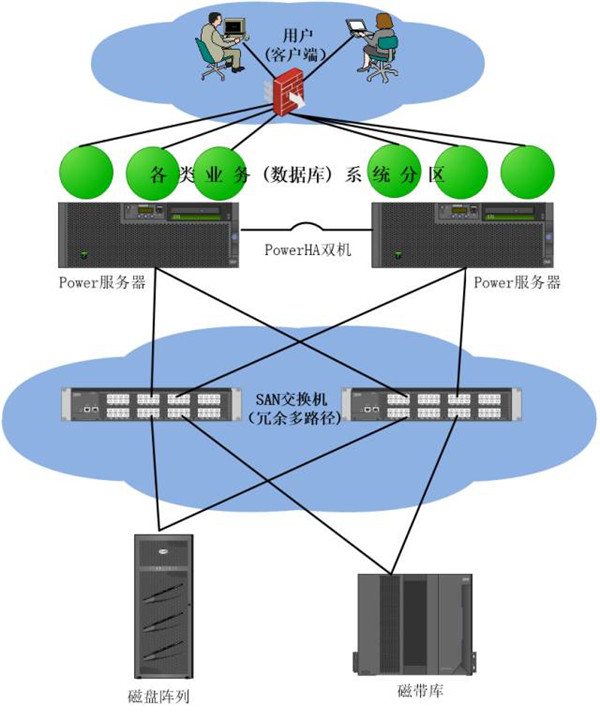
典型IOE架构图
上述为IOE型系统架构,其服务器多使用小型机、大型机(还有以往的中型机);数据库系统往往会使用Oracle;存储则多使用知名品牌的中高端存储阵列、带库等设备。服务器与存储之间多使用SAN存储网络。
这些服务器、存储等硬件本身往往就是双冗余的,线路连线也都是双冗余的,而且设备性能指标往往非常好,例如一台普通中端的Power 7系列服务器可以轻松划分出若干个系统分区或者一二十个虚拟机系统。
B. 开源系统架构
典型的即以使用廉价PC服务器,开源产品技术为主要元素的系统架构。
开源系统架构以横向扩展,分布式部署为特点。常通过向集群中增加单机设备资源解决存储空间、性能以及稳定性问题,其集群规模可以小到两三台PC服务器,也可以大到上万台。
对于数据库,可以通过分布式集群方式解决数据库扩展性的问题。另外非结构化数据库及分布式文件系统在处理非结构化数据的存储与使用方面也很灵活方便。
基于开源系统架构的典型企业如:以BAT(百度、阿里、腾讯)为代表的众多互联网企业。
开源系统架构如图所示:
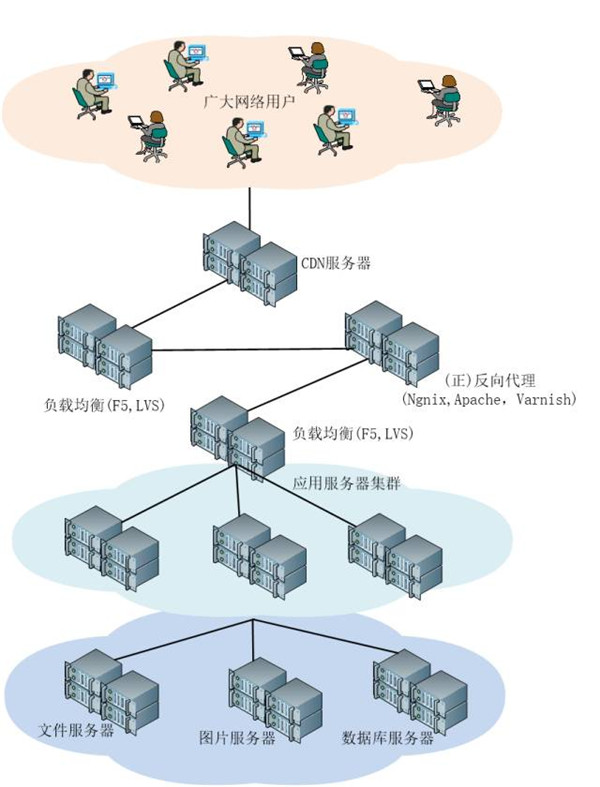
典型开源系统架构图
上述开源系统架构中使用了CDN和反向代理以提高网站性能。
例如我们的服务器可能部署在北京,对于北京及周边用户来说访问是较快的,而对于远离北京的用户访问则感觉较慢,因为数据传输时间比较长。
对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商(或自建CDN)的机房,用户访问时先从最近的CDN机房获取数据,这样大大减少了网络访问的路径。
对于反向代理,当用户请求到达时首先访问反向代理,反向代理服务器将(如:Varnish)缓存的数据返回给用户,如果没有缓存,才会从源站服务器获取,这也减少了获取数据的成本。
当然对于海量访问请求,或庞大集群架构,则就需要分多层,综合运用上述负载均衡以及代理(反代理),同时可能需要引入Zookeeper等功能以协调(服务)任务调度。
从上述架构简析中,我们便会感知到两种运维体系的巨大差异。
俗话说隔行如隔山,现如今就算都是运维这一行,也可谓千山万岭。对于上述基于IOE架构的传统运维体系,对比基于开源架构的互联网运维体系,可以说是当前两大运维阵营。
2、传统运维 vs 互联网运维辨析
一个奇怪的现象
传统运维圈子通常高度认可商业闭源产品。而对开源产品及其技术则很谨慎,很少采纳,甚至认为很多开源产品不上档次。
而互联网运维圈子通常高度青睐开源产品、技术、理念。而对商业闭源产品则比较排斥抵触,再好也不买。
差异可见一斑
传统运维圈子和互联网运维圈子各有特点,同是运维行业,但也有很多差异之处。关于传统运维与互联网运维的不同差异,本文总结了如下几点差异:
A. 架构差异
B. 面向对象差异
C. 运维人员差异
D. 体制理念差异
解析如下:

A. 架构差异
- 传统运维:
传统运维多是围绕以IOE架构及其产品体系进行运维,在性能、数据库、中间件、HA高可用、灾备、存储等环节通常大量采用商业闭源的软硬件产品及其解决方案。
这些方案的特点是通常纵向扩展能力极强,横向扩展能力很弱。商业案例成熟稳定,方案组合重度耦合,讲究两地三中心这种典型的重量级、集中式运维管理方式。
另外IOE架构后面通常有强大的MA维保支持体系,甚至MA人员常年驻场。
- 互联网运维:
互联网运维通常是围绕开源产品、技术解决方案进行运维。在负载性能、数据库、中间件、集群高可用、灾备、分布式存储、自动化部署等环节通常大量采用开源的软件产品及其技术解决方案。
硬件通常使用廉价的X86服务器,甚至白盒产品。
这种开源解决方案通常纵向扩展能力很弱,横向扩展能力很强。有大量社区、行业成熟案例。方案组合灵活,讲究分布式存储、负载集群、轻量级、模块化、去中心化的运维管理方式。
另外互联网系统架构通常缺少MA维保支持。开源产品更新换代甚至消亡的风险较大。
B. 面向对象差异
- 传统运维:
传统行业的IT运维大多是面向企业内部(体系)用户,其需求相对明确、稳定,具有很强的行业系统特点,另外桌面运维中的OA、ERP、MES、企业邮箱等系统,也通常是面相企业内部员工。
因此传统运维面向的用户在其数量、需求、特性通常是可控的、稳定的、集中的。
也因此传统运维圈子适合购买商业产品,这些产品通常是比较成熟的产品,经过长期的测试和使用,有很好地最佳实践,相对能够较好地满足传统运维需求。
- 互联网运维:
相比之下,互联网运维通常面向的是广大互联网用户。因此其面向的对象关系复杂,市场多变,需求五花八门,目的目标不可控,对象海量不可控。
也因此互联网运维的系统环境变更迭代频繁,对自动化、弹性需求要求较高。由于各种复杂多变因素,通常导致传统商业产品不能很好地支撑互联网运维环境。因此被逼无奈只能选择开源,并走自主开发这条路子。
C. 运维人员差异
有服务器的地方就有运维
其实近年来,在这两大运维体系之间流动的运维工程师也不在少数。本文作者就是这两大运维圈子的跨界者。
- 传统运维:
传统运维圈的从业人员,其知识体系普遍比较高逼格。不论其学历背景还是再教育背景通常比较高大上。
同时相关商业产品的培训认证体系也相对完善,传统行业的运维工程师在这方面有其特色。
比如他们通常玩过大型机、VMax、Z/os、Oracle、ITSM、PMP、ISO、PCI、某国加密产品、某国数据库,等等一系列高逼格的玩法。
- 互联网运维:
在互联网运维圈的从业人员,其来历千差万别,既有超人大神,也有小白。他们通常LAMP/LNMP基础扎实,写得一手好脚本,练得一身全栈功夫。
互联网天生具有万众创新的基因,因此这片空间广阔任鸟飞,很多大神往往不是通过各种培训出来的,都是在各种磨练中涅
上一篇:Linux桌面发行版Debian安装起来到底难不难
下一篇:台网融合下的跨屏互动给敏捷开发与运维带来了哪些新挑战?
分享到:
 收藏
收藏
收藏
