大众点评高可用性系统运维经验分享
2016-02-20 19:34:26 来源: 陈一方 美团点评技术团队 评论:0 点击:
本文主要以大众点评的交易系统的演进为主来描述如何做到高可用,并结合了一些团队的运营经验,包括保证比较高的服务可用率,在出现故障时的应对,及时发现、故障转移、尽快从故障中恢复等。需要强调的是,高可用性只是一个结果,应该更多地关注迭代过程,关注业务发展。
所谓高可用性指的是系统如何保证比较高的服务可用率,在出现故障时如何应对,包括及时发现、故障转移、尽快从故障中恢复等等。本文主要以点评的交易系统的演进为主来描述如何做到高可用,并结合了一些自己的经验。需要强调的是,高可用性只是一个结果,应该更多地关注迭代过程,关注业务发展。
可用性的理解
1.理解目标
业界高可用的目标是几个9,对于每一个系统,要求是不一样的。研发人员对所设计或者开发的系统,要知道用户规模及使用场景,知道可用性的目标。比如,5个9的目标对应的是全年故障5分钟。
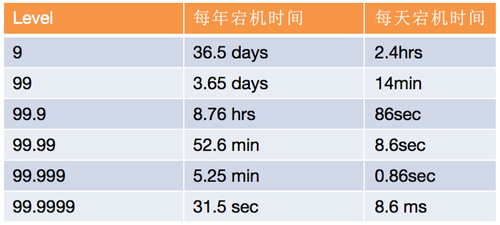
2.拆解目标
几个9的目标比较抽象,需要对目标进行合理的分解,可以分解成如下两个子目标。
(1)频率要低:减少出故障的次数
不出问题,一定是高可用的,但这是不可能的。系统越大、越复杂,只能尽量避免问题,通过系统设计、流程机制来减少出问题的概率。但如果经常出问题,后面恢复再快也是没有用的。
(2)时间要快:缩短故障的恢复时间
故障出现时,不是解决或者定位到具体问题,而是快速恢复是第一要务的,防止次生灾害,问题扩大。这里就要求要站在业务角度思考,而不仅是技术角度思考。
下面,我们就按这两个子目标来分别阐述。
频率要低:减少出故障的次数
设计:根据业务变化不断进行迭代
以点评交易系统的演进过程为例。
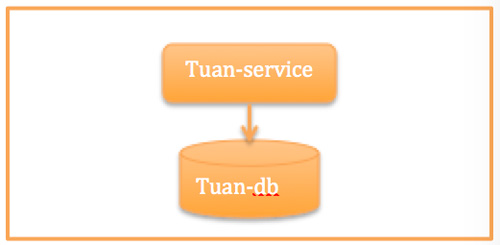
幼儿时期:2012年前
使命:满足业务要求,快速上线。
因为2011年要快速地把团购产品推向市场,临时从各个团队抽取的人才,大部分对.NET更熟悉,所以使用.NET进行了第一代的团购系统设计。毕竟满足业务要求是第一的,还没有机会遇到可用性等质量问题。考虑比较简单,即使都挂了,量也比较小,出现问题,重启、扩容、回滚就解决问题了。
系统架构如下图所示。
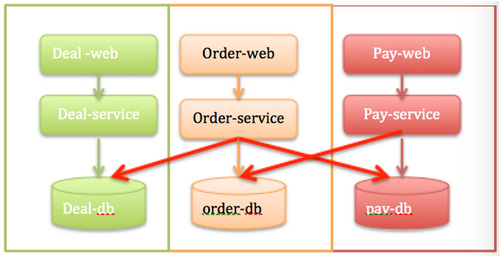
少年时期:垂直拆分(2012-2013)
使命:研发效率&故障隔离。
当2012年在团单量从千到万量级变化,用户每日的下单量也到了万级时候,需要考虑的是迭代速度、研发效率。垂直拆分,有助于保持小而美的团队,研发效率才能更高。另外一方面也需要将各个业务相互隔离,比如商品首页的展示、商品详情页的展示,订单、支付流程的稳定性要求不一样。前面可以缓存,可以做静态化来保证可用性,提供一些柔性体验。后面支付系统做异地容灾,比如我们除了南汇机房支付系统,在宝山机房也部署了,只是后来发现这个系统演进太快,没有工具和机制保证双机房更新,所以后来也不好使用了。
系统演进如下图所示。服务垂直化了,但是数据没有完整隔离开,服务之间还需要互相访问非自己的数据。
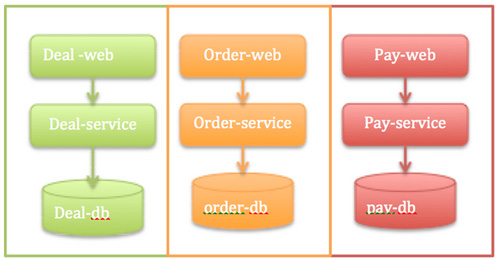
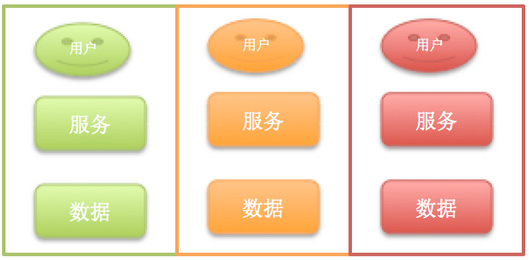
青年时期:服务做小,不共享数据(2014-2015)
使命:支撑业务快速发展,提供高效、高可用的技术能力。
从2013年开始,Deal-service (商品系统)偶尔会因为某一次大流量(大促或者常规活动)而挂掉,每几个月总有那么一次,基本上可用性就在3个9徘徊。这里订单和支付系统很稳定,因为流量在商品详情页到订单有一个转化率,流量大了详情页就挂了,订单也就没有流量了。后来详情页的静态化比较好了,能减少恢复的速度,能降级,但是Deal- service的各个系统依赖太深了,还是不能保证整体端到端的可用性。
所以,2014年对Deal-service做了很大的重构,大系统做小,把商品详情系统拆成了无数小服务,比如库存服务、价格服务、基础数据服务等等。这下商品详情页的问题解决了,后面压力就来了,订单系统的压力增大。2014年10月起,订单系统、支付系统也启动了全面微服务化,经过大约1年的实践,订单系统、促销系统、支付系统这3个领域后面的服务总和都快上百个了,后面对应的数据库20多个,这样能支撑到每日订单量百万级。
业务的增长在应用服务层面是可以扩容的,但是最大的单点——数据库是集中式的,这个阶段我们主要是把应用的数据访问在读写上分离,数据库提供更多的从库来解决读的问题,但是写入仍然是最大的瓶颈(MySQL的读可以扩展,而写入QPS也就小2万)。
这时系统演变成如下图所示。这个架构大约能支撑QPS 3000左右的订单量。
成年时期:水平拆分(2015至今)
使命:系统要能支撑大规模的促销活动,订单系统能支撑每秒几万的QPS,每日上千万的订单量。
2015年的917吃货节,流量最高峰,如果我们仍然是前面的技术架构,必然会挂掉。所以在917这个大促的前几个月,我们就在订单系统进行了架构升级和水平拆分,核心就是解决数据单点,把订单表拆分成了1024张表,分布在32个数据库,每个库32张表。这样在可见的未来都不用太担心了。
虽然数据层的问题解决了,但是我们还是有些单点,比如我们用的消息队列、网络、机房等。举几个我过去曾经遇到的不容易碰到的可用性问题:
服务的网卡有一个坏了,没有被监测到,后来发现另一个网卡也坏了,这样服务就挂了。
我们使用 cache的时候发现可用性在高峰期非常低,后来发现这个cache服务器跟公司监控系统CAT服务器在一个机柜,高峰期的流量被CAT占了一大半,业务的网络流量不够了。
917大促的时候我们对消息队列这个依赖的通道能力评估出现了偏差,也没有备份方案,所以造成了一小部分的延迟。
这个时期系统演进为下图这样:
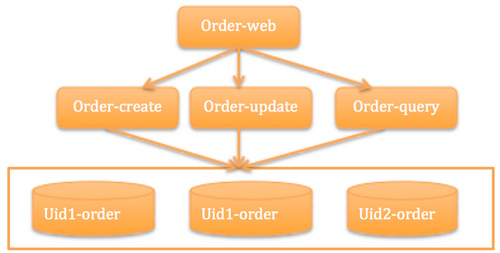
未来:思路仍然是大系统做小,基础通道做大,流量分块
大系统做小,就是把复杂系统拆成单一职责系统,并从单机、主备、集群、异地等架构方向扩展。
基础通道做大就是把基础通信框架、带宽等高速路做大。
流量分块就是把用户流量按照某种模型拆分,让他们聚合在某一个服务集群完成,闭环解决。
系统可能会演进为下图这样:
上面点评交易系统的发展几个阶段,只以业务系统的演进为例。除了这些还有CDN、DNS、网络、机房等各个时期遇到的不同的可用性问题,真实遇到过的就有:联通的网络挂了,需要切换到电信;数据库的电源被人踢掉了,等等。
易运营
高可用性的系统一定是可运营的。听到运营,大家更多想到的是产品运营,其实技术也有运营——线上的质量、流程的运营,比如,整个系统上线后,是否方便切换流量,是否方便开关,是否方便扩展。这里有几个基本要求:
可限流
线上的流量永远有想不到的情况,在这种情况下,系统的稳定吞吐能力就非常重要了,高并发的系统一般采取的策略是快速失败机制,比如系统QPS能支撑 5000,但是1万的流量过来,我能保证持续的5000,其他5000我快速失败,这样很快1万的流量就被消化掉了。比如917的支付系统就是采取了流量限制,如果超过某一个流量峰值,我们就自动返回“请稍后再试”等。
无状态
应用系统要完全无状态,运维才能随便扩容、分配流量。
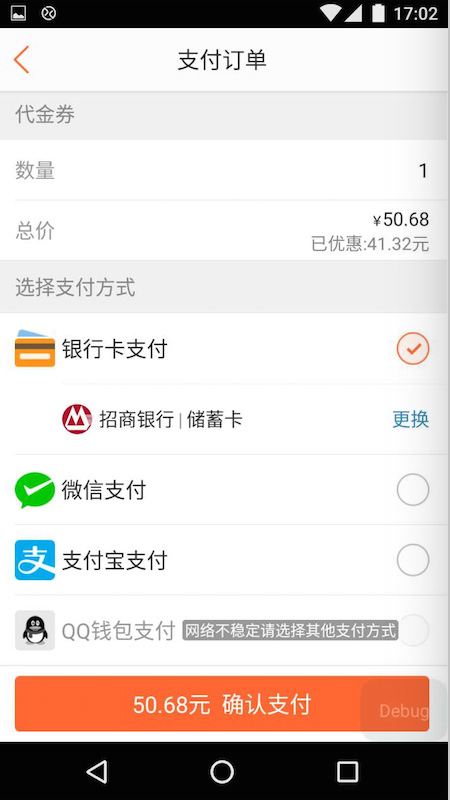
降级能力
降级能力是跟产品一起来看的,需要看降级后对用户体验的影响。简单的比如:提示语是什么。比如支付渠道,如果支付宝渠道挂了,我们挂了50% ,支付宝旁边会自动出现一个提示,表示这个渠道可能不稳定,但是可以点击;当支付宝渠道挂了100% ,我们的按钮变成灰色的,不能点击,但也会有提示,比如换其他支付渠道(刚刚微信支付还挂了,就又起作用了)。另一个案例,我们在917大促的时候对某些依赖方,比如诚信的校验,这种如果判断比较耗资源,又可控的情况下,可以通过开关直接关闭或者启用。
可测试
无论架构多么完美,验证这一步必不可少,系统的可测试性就非常重要。
测试的目的要先预估流量的大小,比如某次大促,要跟产品、运营讨论流量的来源、活动的力度,每一张页面的,每一个按钮的位置,都要进行较准确的预估。
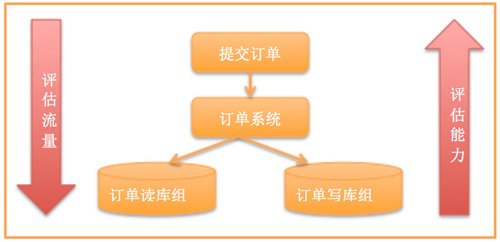
此外还要测试集群的能力。有很多同学在实施的时候总喜欢测试单台,然后水平放大,给一个结论,但这不是很准确,要分析所有的流量在系统间流转时候的比例。尤其对流量模型的测试(要注意高峰流量模型跟平常流量模型可能不一致)系统架构的容量测试,比如我们某一次大促的测试方法。
从上到下评估流量,从下至上评估能力:发现一次订单提交有20次数据库访问,读写比例高峰期是1:1,然后就跟进数据库的能力倒推系统应该放入的流量,然后做好前端的异步下单,让整个流量平缓地下放到数据库。
降低发布风险
严格的发布流程
目前点评的发布都是开发自己负责,通过平台自己完成的。上线的流程,发布的常规流程模板如下:
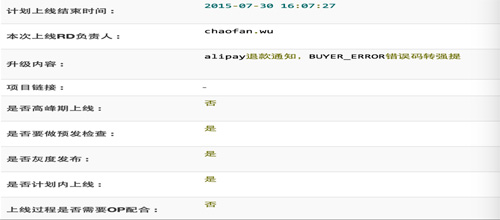
灰度机制
服务器发布是分批的,按照10%、30%、50%、100%的发布,开发人员通过观察监控系统的曲线及系统的日志,确定业务是否正常。
线上的流量灰度机制,重要功能上线能有按照某种流量灰度上线能力。
可回滚是标配,最好有最坏情况的预案。
时间要快:缩短故障的恢复时间
如果目标就要保证全年不出故障或者出了故障在5分钟之内能解决,要对5分钟进行充分的使用。5分钟应该这样拆解:1分钟发现故障,3分钟定位故障出现在哪个服务,再加上后面的恢复时间。就是整个时间的分解,目前我们系统大致能做到前面2步,离整体5个9的目标还有差距,因为恢复的速度跟架构的设计,信息在开发、运维、DBA之间的沟通速度及工具能力,及处理问题人员的本身能力有关。
生命值:

持续关注线上运行情况
熟悉并感知系统变化,要快就要熟,熟能生巧,所以要关注线上运营情况。
了解应用所在的网络、服务器性能、存储、数据库等系统指标。
能监控应用的执行状态,熟悉应用自己的QPS、响应时间、可用性指标,并对依赖的上下游的流量情况同样熟悉。
保证系统稳定吞吐
系统如果能做好流量控制、容错,保证稳定的吞吐,能保证大部分场景的可用,也能很快地消化高峰流量,避免出现故障,产生流量的多次高峰。
故障时
快速的发现机制
告警的移动化
系统可用性的告警应该全部用微信、短信这种能保证找到人的通信机制。
告警的实时化
目前我们只能做到1分钟左右告警。
监控的可视化
我们系统目前的要求是1分钟发现故障,3分钟定位故障。这就需要做好监控的可视化,在所有关键service里面的方法层面打点,然后做成监控曲线,不然3分钟定位到具体是哪个地方出问题,比较困难。点评的监控系统CAT能很好的提供这些指标变化,我们系统在这些基础上也做了一些更实时的能力,比如订单系统QPS就是秒级的监控曲线。
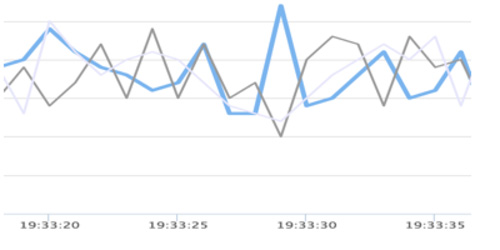
有效的恢复机制
比如运维的四板斧:回滚、重启、扩容、下服务器。在系统不是很复杂、流量不是很高的情况下,这能解决问题,但大流量的时候就很难了,所以要更多地从流量控制、降级体验方面下功夫。
几点经验
珍惜每次真实高峰流量,建立高峰期流量模型。
因为平常的压力测试很难覆盖到各种情况,而线上的真实流量能如实地反映出系统的瓶颈,能较真实地评估出应用、数据库等在高峰期的表现。
珍惜每次线上故障复盘,上一层楼看问题,下一层楼解决问题。
线上出问题后,要有一套方法论来分析,比如常见的“5W”,连续多问几个为什么,然后系统思考解决方案,再逐渐落地。
可用性不只是技术问题。
系统初期:以开发为主;
系统中期:开发+DBA+运维为主;
系统后期:技术+产品+运维+DBA。
系统较简单、量较小时,开发同学能比较容易地定位问题并较容易解决问题。
当系统进入较复杂的中期时,就需要跟运维、数据库的同学一起来看系统的瓶颈。
当系统进入复杂的后期时,系统在任何时候都要考虑不可用的时候如何提供柔性体验,这就需要从产品角度来思考。
单点和发布是可用性最大的敌人。
可用性要解决的核心问题就是单点,比如常见的手段:垂直拆分、水平拆分、灰度发布;单机到主备、集群、异地容灾等等。
另外,系统发布也是引起系统故障的关键点,比如常见的系统发布、数据库维护等其他引起系统结构变化的操作。
【编辑推荐】
【责任编辑:火凤凰 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
