百度多维度数据监控采集和聚合计算的运维实践分享(1)
2016-02-20 19:33:47 来源: 颜志杰 StuQ 评论:0 点击:
我是百度运维部平台研发工程师颜志杰,毕业后一直在百度做运维平台开发,先后折腾过任务调度(CT)、名字服务(BNS)、监控(采集&计算);今天很高兴和大家一起分享下自己做“监控”过程中的一些感想和教训。
算子可以这么设计是因为计算avg不受影响,avg=sum/count,把10s sum加起来,和先加2s的sum,然后2s中间结果再加起来,除以count,精度没有损失,但分位值有精度损失,这个需要权衡。
storm算子设计就介绍到这,下面开始介绍数据上卷操作。
数据上卷在接入层做数据一维打平,在接入层的时候按照名字服务的圈定范围变成了多份自包含数据,比如实例1=>服务2=>服务组3,那么来自实例1的数据就变成两条数据。
这两条数据一个范围属于服务2,一个属于范围服务组3,其他都一样,也就是牺牲了计算资源,保证整个计算数据都是不相关的,这个其实是有优化空间的,大家可以自己考虑。
到这里多维度采集&计算基本功能点介绍完了。下面就介绍下稳定性的考虑了。
此处有图:
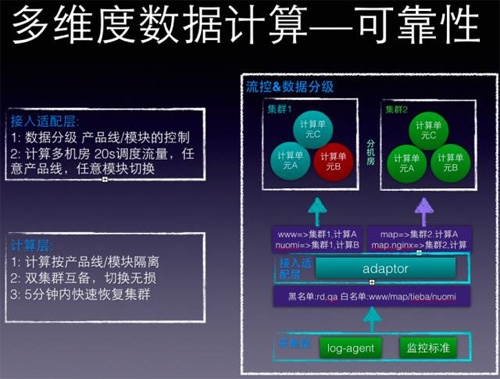
前面一直强调数据符合28定律,所以这个系统首先要支持流控,支持按数据重要性做优先级处理,有如下措施:
第一,接入adaptor层,实现按产品线作为流控基本单元,和使用统计,谁用的多就必须多出银子,通过设置黑白名单,当出现紧急情况下,降级处理。
第二,聚合计算做成整个无状态,可水平扩展,多机房互备,因为kafka+storm不敢说是专家,所以在应用架构上做了些文章,主要为:
数据按照名字服务的范围圈出来后,我们发现,只要保证圈出来的“同一范围”的数据保证在同一个计算单元计算,就没有任何问题。
比如建立两个机房集群1,2,每个机房建立3个kafka topic/ storm计算单元,取名为A,B,C计算单元,通过adaptor,将接收的数据做映射,可以有如下映射:
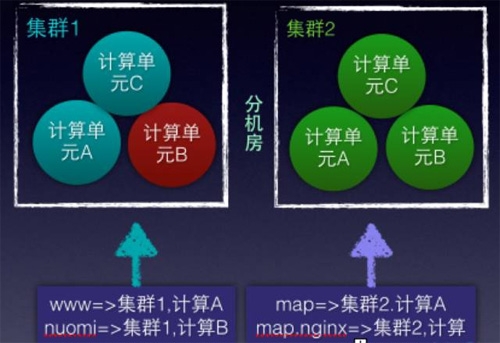
比如地图产品线的接入服务,命名为:map.nginx,只要范围map.nginx的数据映射到一个计算单元即可,可以用如下规则:map.nginx接入 => 集群2,1计算单元A
这样所有map的接入nginx数据就直接将数据写入到集群2机房的A计算单元来完成,集群2的计算单元B挂了,当然不会影响map.nginx。
总结来说,整个计算都是无状态,可水平扩展;支持流控,当有异常时,可以进行双机房切换,如果有资源100%冗余,如果没有,就选择block一些产品线,服务降级。
到这里,整个多维度监控采集和计算介绍完成了:)下面说一下总结和展望吧!

采集就是一个标准化的过程,文本用命名正则其实是无奈之举,期望是pb日志,这样不会因为日志变动导致正则失效,而且性能也会提升;APM也是一样,这个类似于lib的功能,不用通过日志能采到核心数据。
个人很看好pb日志,如果能够有一个通用的pb模板,有一个pb日志的规范推得好,那么还是很有市场的,以后只要这么打日志,用这个模板的解析,就能得到很多内部的数据,不用写正则。
采集就是一个标准之争的权衡,估计你不会骂linus大神为啥把进程监控信息用文本放在/proc/pid/stat,而且进程名为啥只有16个字节;标准就在那,自己需要写agent去将这个标准转换为你内部的标准。
当你自己推出了监控标准,在公司内部用的很多的时候,RD/op需要努力的去适配你了,他们需要变换数据格式到监控标准上;所以,到底是谁多走一步,这个就需要看大家做监控的能力了:)
聚合计算的考虑则是各种算子的丰富,比如uv,还有就是二次计算,就是在storm计算的数据之上,再做一次计算;比如服务=>服务组的上卷操作可以通过二次计算来完成。
比如服务组包含了服务1、服务2,那么我们可以先只计算服务1、服务2的pv数据,然后通过二次计算,算出整个服务组的pv数据 ,由于二次计算没有大数据压力,可以做的支持更多的算子,灵活性,这个就不展开了。
我总结一下:
1.28定律,监控需要倾斜资源处理“关键”指标数据。
2.关键指标数据需要多维度观察,1点变多点,这些数据是相互关联,需要进行meta和配置管理。
3.系统设计时,数据模型先行,功能化、服务化、层次化、无状态化。
4.对开源系统的态度,需要做适配,尽可能屏蔽开源细节,除了啃源码之外,在整个应用架构上做文章,保证高可用性。
答疑环节
1.抓取数据的时候需要客户端装agent?必须要agent吗?
从两方面回答这个问题吧!首先系统设计的是层级化的,你可以不用agent,直接推送到我们的计算接入层;其次,如果你的数据需要采集,那么就是一个标准化的适配过程,比如你的监控数据以http端口暴露出来,那么也需要另一个人去这个http端口来取,手段不重要,重要的是你们两个数据的转换过程,所以不要纠结有没有agent,这个事情谁做都需要做。
2.采集之后,日志是怎么处理的?
日志采集后,通过命名正则进行格式化,变成k:v对,然后将这些k:v对作为类似参数,直接填写到多维度数据模型里面,然后发给聚合计算模块处理。相当于对日志里面相同的字段进行统计,上面说的比如地图nginx日志的处理就是这样。
3.elesticsearch+logstash百度有木有在用呢?还有kafka在百度运维平台中的使用是什么状态呢?
ELK在小产品线有使用,这个多维度监控可以大部分的情况下替换ELK,而且说的自信点,我们重写的agent性能快logstash十倍,而且符合我们的配置下发体系,整个运维元数据定义等;kafka在刚刚的系统里面就是和storm配合作为聚合计算的实现架构。
但我想强调的是,尽量屏蔽开源细节,在kafka+storm上面我们踩过不少坑。通过上面介绍的这种应用框架,可以保证很高的可靠性。
4.多维度数据监控在哪些场景会用的到,可以详细说下几个案例吗?
我今天讲的是多维度数据监控的采集和计算,没有去讲这个应用,但可以透露一下,我们现在的智能监控体系都是在刚刚讲的这一套采集&计算架构之上;每层都各司其职,计算完成后,交给展示/分析一个好的数据模型,至于在这个模型上,你可以做根因定位,做同环比监控,这个我就不展开了。
5.能介绍百度监控相关的数量级吗?
这个就不透露了,但大家也都知道BAT三家的机器规模了,而且在百度运维平台开发部门,我们的平台是针对百度所有产品线;所以,有志于做大规模数据分析处理的同学,你肯定不会失望(又是一个硬广:)
6.不同产品线的聚合计算规则是怎么管理的。不同聚合规则就对应这不同的bolt甚至topology,怎么在storm开发中协调这个问题?
看到一个比较好的问题,首先我们设计的时候,是通用聚合计算,就计算sum/count/avg/min/max分位值,常见的运维都可以涵盖;我们通过agent做了公式计算,表达能力也足够了,同时有二次计算。不一定非要在storm层解决。
我提倡“正确的位置解决问题”,当然大家对这个正确位置理解不同。
7.topology无状态这句话没太明白。storm topology的状态管理不是自身nimbus控制的吗?百度的应用架构在此做了哪些工作或者设计?
我说的是写的storm算子是无状态的,整个数据都是自包含的,我们在应用架构上,就是控制发给stormtopology的数据;多机房互备等;我说的应用架构师在这个storm之上的架构。相当于我认为整个storm topology是我接入adaptor层的调度单元。
【编辑推荐】
【责任编辑:火凤凰 TEL:(010)68476606】
分享到:
 收藏
收藏
收藏
