百度多维度数据监控采集和聚合计算的运维实践分享(1)
2016-02-20 19:33:47 来源: 颜志杰 StuQ 评论:0 点击:
我是百度运维部平台研发工程师颜志杰,毕业后一直在百度做运维平台开发,先后折腾过任务调度(CT)、名字服务(BNS)、监控(采集&计算);今天很高兴和大家一起分享下自己做“监控”过程中的一些感想和教训。

大家好,我是百度运维部平台研发工程师颜志杰,毕业后一直在百度做运维平台开发,先后折腾过任务调度(CT)、名字服务(BNS)、监控(采集&计算);今天很高兴和大家一起分享下自己做“监控”过程中的一些感想和教训。
现在开始本次分享,本次分享的主题是《多维度数据监控采集&计算》,提纲如下,分为3个部分:
1.监控目标和挑战
2.多维度数据监控
2.1.采集的设计和挑战
2.2.聚合计算的设计和挑战
2.3.高可用性保障设计
3.总结&展望
首先进入第一部分 :监控目标和挑战,先抛出问题,装装门面,拔高下分享的档次(个人理解,欢迎challenge)。
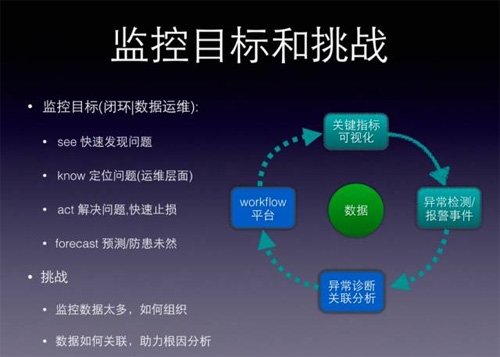
监控期望做到:快速发现问题,定位问题(运维层面),解决问题,甚至要先于问题发生之前,预测/防患未然,形成处理闭环,减少人工决策干预。
先解释一下“定位问题(优先运维层面)”,意思是站在运维角度“定义故障”,不需要定位到代码级别的异常,只需定位到哪种运维操作可以恢复故障即可,比如确定是变更引起的,则上线回滚,机房故障则切换流量等…
不是说监控不要定位到代码级别的问题,事情有轻重缓急,止损是第一位,达到这个目标后,我们可以再往深去做。
再解释下“预测/防患未然”,很多人第一反应是大数据挖掘,其实有不少点可以做,比如将变更分级发布和监控联动起来,分级发布后,关键指标按照“分级”的维度来展示。(记住“分级”维度,先卖个关子:)
“监控目标”这个话题太大,挑战多多。收敛一下,谈一下我们在做监控时,遇到的一些问题,挑两个大头,相信其他在大公司做监控的同学也有同感:
1.监控指标多,报警多
2.报警多而且有关联,如何从很多异常中找出“根因”
今天先抛出来两个头疼的问题,下面开始进入正题“多维度数据监控”,大家可以带着这两个问题听,看方案是否可以“缓解”这两个问题。
进入正题:
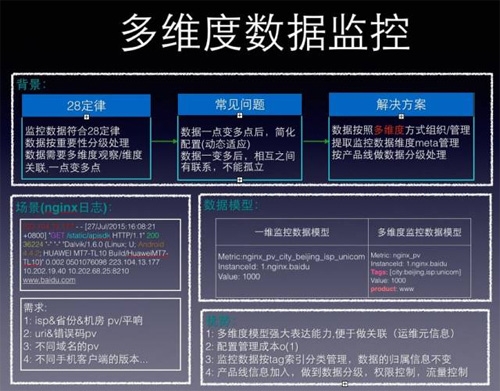
先看第一个问题:监控数据多。监控数据符合28定律,“关键”和“次要”指标需要区别对待,不能以处理了多大数据量引以为傲,需要按重要性分级处理,将资源倾斜到重要数据上分析和处理。
分享到:
 收藏
收藏
收藏
