新浪微博王传鹏:微博推荐架构的演进(1)
2016-02-20 19:33:33 来源: 王传鹏 51CTO 评论:0 点击:
在微博推荐发展的过程中遇到体系方向的变化、业务的不断更迭、目标的重新树立,其产品思路、架构以及算法也随之进行变迁。本文主要阐述在这个过程中推荐架构的演进,从产品目标、算法需求以及技术发展等维度为读者呈现一个完整的发展脉络,同时也希望通过这个机会跟大家一起探讨业务与技术的相互关系。

王传鹏 新浪微博推荐及广告技术总监
| 王传鹏,WOT峰会特邀嘉宾,曾为第七届WOT移动互联网开发者大会的特约讲师,也是本届“互联网+”时代大数据技术峰会的联合出品人之一。2006年从北航毕业,然后加入霍尼韦尔北京研中心做工程,之后同合伙人一起创办云存储网络硬盘(99盘)。在公司被收购后,加入当当网负责推荐和广告工作。于2011年加入新浪微博商业产品部,负责推荐和广告,直至现在。 |
引言
微博(Weibo)是一种通过关注机制分享简短实时信息的广播式社交网络平台。微博用户通过关注来订阅内容,在这种场景下,推荐系统可以很好地和订阅分发体系进行融合,相互促进。微博两个核心基础点:一是用户关系构建,二是内容传播,微博推荐一直致力于优化这两点,促进微博发展。如图1所示:
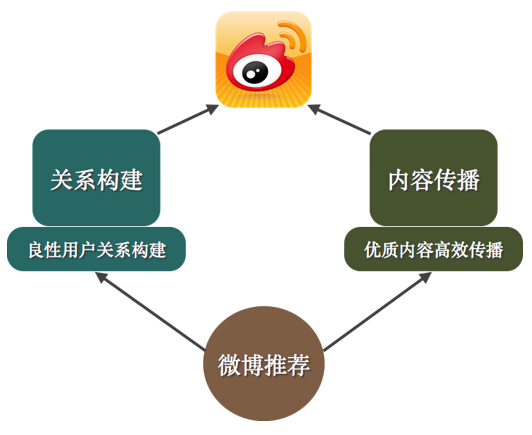
图1 微博推荐的使命
在微博推荐发展的过程中遇到体系方向的变化、业务的不断更迭、目标的重新树立,其产品思路、架构以及算法也随之进行变迁。本文主要阐述在这个过程中推荐架构的演进,从产品目标、算法需求以及技术发展等维度为读者呈现一个完整的发展脉络,同时也希望通过这个机会跟大家一起探讨业务与技术的相互关系。
为了便于理解微博推荐架构演进,在介绍之前需要陈述一下微博推荐在流程上的构成,其实这个和微博本身没有关系,理论上业内推荐所存在的流程基本都是相同的。如图2所示,推荐是为了解决用户与item之间的关系,将用户感兴趣的item推荐给他/她。那么,一个item被推荐出来会经过候选、排序、策略、展示、反馈到评估再改变候选等等形成一个完整的回路。
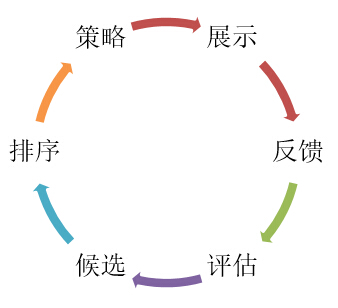
图2推荐的链路
在上述整体流程的基础上,微博推荐架构经历了如图3所示的三个阶段:
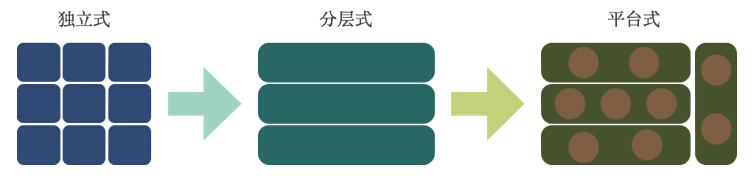
图3 微博推荐架构的三个阶段
通常架构的产生都会来自于团队和业务环境,源于环境因素而致力于解决环境中的问题,架构形成会带着较为强烈的特点,在其实施中会产生交给针对性的效果。本文将从环境因素、架构组成与特点以及实施效果这三个方面进行阐述微博推荐的三个阶段。
1 独立式的1.0
1.1 环境
影响架构形成的环境因素可以分为内部环境因素以及外部环境因素。内部因素主要是团队及其成员相关内容,而外部因素主要来自于外部门、整个公司或者整个行业领域。
微博推荐1.0的这段时间是从2011年7月份到2013年2月份左右,其主要的目标就是实现当前的业务需求。对于独立式的解释:每一个业务项目都是一套完整架构流程,架构之间相对独立,甚至包括技术栈。之所以称之为独立式其内部因素有几点:
1) 当时团队是一个新团队,成员也相对较新,相互的合作不多,缺乏推荐领域整体性经验。
2) 团队成员对于推荐架构都有自己的一些或多或少的理解,但是对于在当前场景下的微博推荐架构,共识并没有形成。
当然起决定性因素的还是外部环境,是因为内部原因还是比较好协调和进化的。当时的外部环境因素包括:
1) 项目需求很多,在当时一个5人团队并行开发的项目平均在3-5个左右,当然最重要的因素是当时的微博产品正处于高速发展期,很多地方都需要微博推荐的支撑。同时,项目周期也很短,排期仓促,很难有时间进行细致的整理和抽象。典型产品包括:微吧、微群、微刊、微话题、用户以及内容排序等等。
2) 团队是一个支撑性的,绝大部分需求来自于外部团队,各个外部团队不同的产品方向也导致疲于应付需求。
3) 当时业内的推荐架构也有不同的发展方向,大家都在尝试摸索一些符合自身发展的架构思路。
由于上述的那些原因,通常我们面对一个接一个的项目时,都会根据自己的理解使用熟悉的技术栈来搭建流程,这样形成了一个又一个的独立架构。
1.2 架构组成与特点
上节中提到了独立架构形成的原因,大家可能觉得架构组成没有必要去描述了,这是不对的,事实上后来的分层以及平台架构的基础恰恰都来源于这个阶段,没有这个阶段团队不断踩坑总结就没有因地制宜产生的后续进化。因此,我们需要为大家剖析一下推荐1.0的架构组成与特点。
1) 技术目标
参考图2所示,以业务实现为主要目标的微博推荐1.0,没有建立起完整的反馈以及评估体系,同时排序也是被策略取代,那么讲主要的重点体现到了候选、策略以及展现上。上述推荐流程被转化为:候选策略展现简单形态。
2) 架构组成
如图4所示,我们试图将每个项目的架构能够在图中表达出来,在真正的实施过程中,每一个项目负责人会选择使用apache+mod_python作为服务架构同时,使用redis作为存储选型。在一些特定的项目中,引入了复杂运算从而诞生了c/c++的服务框架woo;同时,对于数据的存储要求特型化的项目中又自己研发了一系列的db,比如早期存储静态数据的mapdb,存储key-list的keylistdb等等。当然,在部署中会比下图更加随意一些,一个项目几台服务器部署好微博服务提供http请求,然后再找几个服务器安装redis作为数据支撑,来源数据和业务方定好规则使用rsync传输就OK了,大部分策略在python中实现。
图中可以看到主要的技术栈:
- web服务:apache+mod_python,后来发展成为社区更为完善的mod_wsgi。使用python作为WEB开发语言主要是因为平时处理数据使用的都是python,同时上手快,学习曲线平缓。
- 运算服务:c/c++,形成woo内部服务框架
- db:redis/mapdb/keylistdb等等,分为两种存储方法:redis以及自研型
- 数据来源:rsync文件传输,firehose作为微博相关内容来源[微博内部使用的一种数据队列]
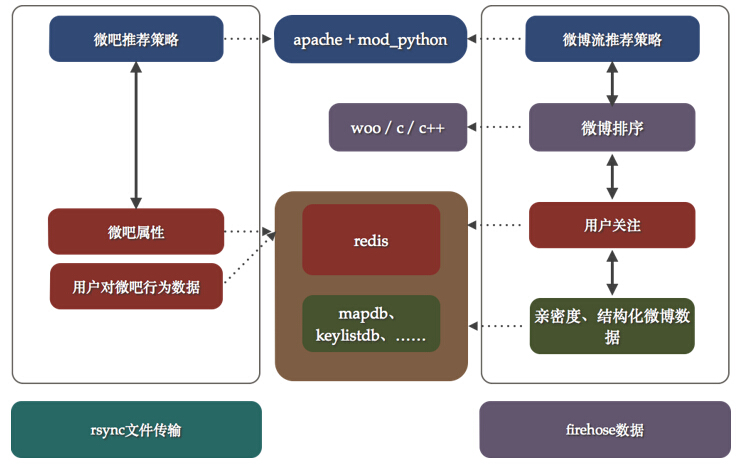
图4 微博推荐1.0架构简图
3) 架构特点
将架构特点划分为优点和缺点进行描述。那么优点是:
- 简单,易于实现,不需要额外的基础支撑
- 利于业务的功能快速实现
- 利于多业务并行开展,相互不影响
而不足是:
- 推荐流程不完整,缺乏反馈、评估等等重要内容,对于数据方面也极度缺乏统一处理方法
- 没有提供给算法相关的支撑,很难将推荐做的深入
- 几乎无法进行专业运维
- QA的测试仅仅能到功能层面,模块级别的测试几乎不可能,因为太过于分散
- 很难进行团队协作,不利于项目的分解
1.3 成果
尽管存在诸多的缺点,但是在其发展的过程中,也给后面的架构优化奠定了基础,其成果如下:
1) 在微博高速发展的过程中,满足了微博对于推荐的业务支撑要求,在这段时期里面共完成二十多个独立项目。
2) 诞生了woo的基础框架,后面的内部高效运算框架来源于此
3) 诞生了mapdb的静态存储,成为后期微博推荐静态存储的雏形
4) web应用层的不断需求的总结,组建形成推荐通用应用框架
分享到:
 收藏
收藏
收藏
